As Large Language Models (LLMs) continue to evolve, the way we write and consume documentation is undergoing a significant shift. Until recently, most documentation was written for human eyes — clear, explanatory, and navigable. But in today’s digital landscape, LLMs are emerging not just as readers, but as the primary consumers of technical documents.
Gartner predicts that by 2026, over 30% of the growing demand for APIs will come not from human developers, but from AI agents and tools powered by LLMs. This isn’t just speculation—it’s a rapidly accelerating trend that suggests machines may soon surpass humans as the primary consumers of APIs. As LLMs take on the role of autonomous software users, the very purpose of documentation is shifting. It’s no longer just about helping humans understand; it’s about structuring information in ways that machines can interpret, reason over, and act upon.
One of the clearest signs of this shift is the emergence of files like lm.txt. Inspired by robots.txt, which tells crawlers what to index, lm.txt is a lightweight Markdown file designed to guide language models. It gives a high-level overview of how a website works — its APIs, authentication methods, and contact points — all in a format that’s easy for a model to parse. It’s not built for people. It’s built for LLMs.
# Welcome to our developer hub
- APIs documented in OpenAPI format
- Authentication uses OAuth 2.0
- Contact: support@yourcompany.com
Another sign is how tools like Gitingest have emerged to convert complex Git repositories into digestible summaries. These summaries make it easier for LLMs to understand large codebases without having to parse hundreds of files directly. Instead of raw code, they’re fed structured, intentional representations of what’s going on. That means better documentation, better reasoning, and fewer errors when LLMs are used for code review, explanation, or testing.
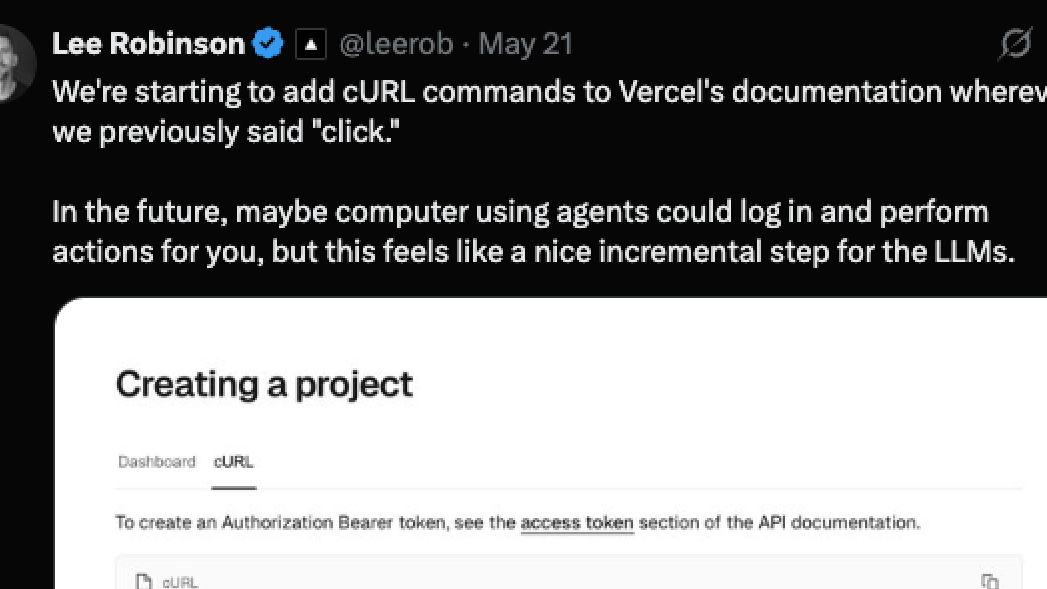
But the shift doesn’t stop at reading. LLMs are starting to take actions, too. Vercel — a popular frontend cloud platform — now exposes most user interactions as cURL commands. That means an LLM can simulate clicks, deployments, and settings adjustments by issuing simple API calls. What was once a graphical click is now a command — a shift that opens the door to agent-like behavior. LLMs no longer just observe; they do.
curl -X POST https://vercel.com/api/deploy \
-H "Authorization: Bearer <token>" \
-d '{ "project": "my-app" }'
Of course, this opens up new risks. If an LLM is empowered to act based on documentation, that documentation must be secure, unambiguous, and trustworthy. A vague or misleading API spec could result in a language model making incorrect assumptions or unsafe calls. Proper rate-limiting, authentication, and boundary setting become crucial. As we grant LLMs more autonomy, we must also invest in more rigorous validation and safety mechanisms.
Still, this evolution is exciting. We’re witnessing the beginning of a new kind of document — one that doesn’t just inform, but enables. One that’s written with clarity, consistency, and machine-readability from the ground up. As LLMs become more capable, and as more workflows are handed over to them, the way we document will continue to change.
Isn’t it exciting to imagine what the next generation of API documentation will look like?
References
- Gartner Predicts More Than 30% of the Increase in Demand for APIs will Come From AI and Tools Using Large Language Models by 2026
- YouTube – Vercel AI: Designing for LLM-first UX (from 33:39) → Covers that Vercel is exposing user interactions as cURL for LLM automation